

Think about the questions you type into Google. Chances are, you’re looking for instant answers to simple questions. You might look through a few different pages of results to confirm findings, but if the search engine has done its job correctly, you only need one result to be satisfied.
Now think about the types of questions researchers attempt to answer when they use search engines. The experience is far more complex than a simple query with an instant answer.
When a researcher tasked with understanding all the genes that are involved in a disease or pathway, or all the compounds that inhibit a target, or all the different ways that patients talk about a drug on the marketplace, a casual scan of top results isn’t good enough. A comprehensive, systematic view of all the information that’s out there is the only way to make an accurate claim.
So how can researchers cope with the deluge of data at their disposal and search more efficiently? Here’s a look at several key scientific search concepts:
Aggregated Search
Aggregated search is designed to bring together multiple, unlike information sources. There could be structured or semi-structured data – such as feeds or APIs that provide company-, drug-, or clinical trial-related information.
Aggregated search presents multiple information types to end users, enabling them to explore different types of content as well as visualizations, analytics, or extracted information. These act as signposts for users, helping them to explore the information and direct themselves to the most appropriate resources for their question.
Here’s an example:
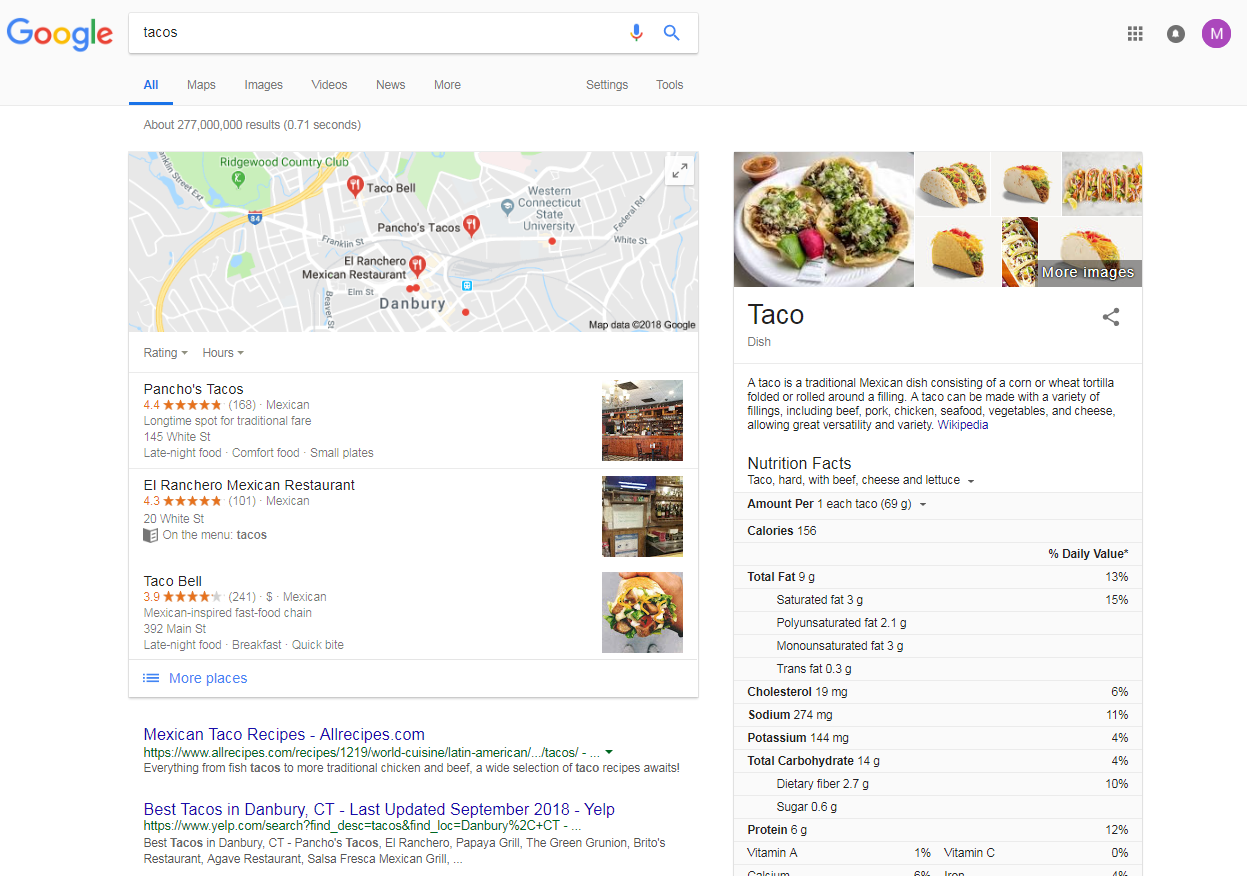
Google provides relevant examples of this from a consumer search perspective, displaying location and commercial information alongside summary information boxes and in context of the traditional list of web links, while also allowing access to specific media types such as images and videos.
Related Reading: How Does Aggregated Search Work?
Personalized Search
Personalization is about tailoring the user experience by leveraging signals collected through user interaction with a system. More specifically, personalized search is about tailoring the search experience to the user by considering the user’s context in addition to the submitted query.
This can be accomplished through explicit data knowingly provided by the user or administrators, such as user profiles that include topics of interest or areas of specialty, or through implicit signals the user provides as they go about retrieving information – such as submitting queries, filtering, and clicking on results.
The goal of personalized search is to help users find what they need faster.
Contextualized Search
Contextualized search is similar but broader in scope to personalized search.
Contextualization means that the system considers the context of an interaction – such as organization, location, and information about the user – to improve the quality of the system’s output – such as a set of search results, or overall user experience.
Enterprise Search
This is a search across enterprise information, contrasted with – for example – web search.
Federated Search
Federated search technology has a long history. It is an approach to integrating information sources for information retrieval that relies on the system to take the user’s query and submit it to various underlying data sources. The federated search system then compiles the results from the different sources and presents them to the user in a single, unified relevance sorting.
One problem with federated search is that it presumes the underlying data is largely alike – such as being all text data, for example. This means that many rich sources of information and insights for R&D users – such as semi-structured drug pipeline data, competitive intelligence information, and other content – may not be included or effectively integrated in such systems.
A second problem is that the unified relevance sorting approach presents information all together. This may inhibit the user’s ability to explore different information types or get direct answers to questions.
The Future of Search
For R&D teams, the ability to seek (and more importantly, find) information is central to success. Regardless of information being internal or external, structured or unstructured, information management and informatics professionals need to work toward the goal of removing information roadblocks, and creating a clear path to the content they seek.
Ready to learn more? Check out:
- The Evolution and Importance of Biomedical Ontologies for Scientific Literature.
- Using AI-powered Text Mining to Re-use Research Insights Published in Scientific Literature
- 5 Things Modern Researchers Want in a Search Tool
RightFind® Insight, powered by the SciBite® platform, brings the power of semantic enrichment to the search and reading experience to turn information into knowledge and accelerate new discoveries. Learn more here.
