

For publishers embracing the transition to open access (OA) business models, understanding historical customer publication and subscription spend—and communicating that data efficiently and transparently to nurture institutional trust—is mission critical. Although the rapid uptake of OA agreements between publishers and institutions is a sign the industry is advancing OA goals in a meaningful way, an institutional deal is only as good as its underlying data. Otherwise, the parties risk building agreements on a faulty foundation.
By way of example, a key indicator of successful deals is the ability to match manuscripts to available OA funding sources. The need to assert and validate author affiliation at the manuscript level for funding eligibility in a more precise and granular manner is only going to intensify under the OSTP mandate for US research funding agencies as well as Plan S and similar UKRI initiatives.
The performance of an OA agreement of any kind, whether transformative or pure, depends on the quality of the metadata flowing through the research lifecycle. As a basis for modeling and negotiating new deals or renewals, tracking author, institutional, and funder associations to research output is vitally important to accurately connect manuscripts to potential open access funding sources. And we know it is becoming increasingly common for multiple sources of funding under multiple agreements to exist within institutions and across coauthors, making the circumstances even more complex.
It’s a well-known fact among industry professionals that capturing and preserving institutional, funder, and grant IDs inadequately throughout the research workflow is particularly problematic when modeling and paying for OA. We see this to a degree in facilitating hundreds of agreements through the RightsLink for Scientific Communications (RLSC) platform. Whether captured inconsistently early in grant management, missed entirely, or dropped at a later stage of the publishing lifecycle, gaps exist that must be closed for the global transformation to work. Moreover, as mandates change, data previously not needed becomes critically important. This is especially true with the new OSTP policy which will require compliance for all authors on a manuscript.
The charts below represent all accepted manuscripts in the RLSC system over the past five years, and the data clearly show progress across publishers in associating manuscripts to institutions and to funders. On the left, the volume of manuscripts with institutional and funder associations (the dark blue line in the middle) grows proportionally to the total volume of accepted manuscripts (the light blue line on the top). Similarly, the dark blue bars on the bottom of the right-hand chart show that identifiers and email domains are present on 82% of total accepted manuscripts in 2021, up from 52% in 2017.
Author Affiliation and Funder Data Trends
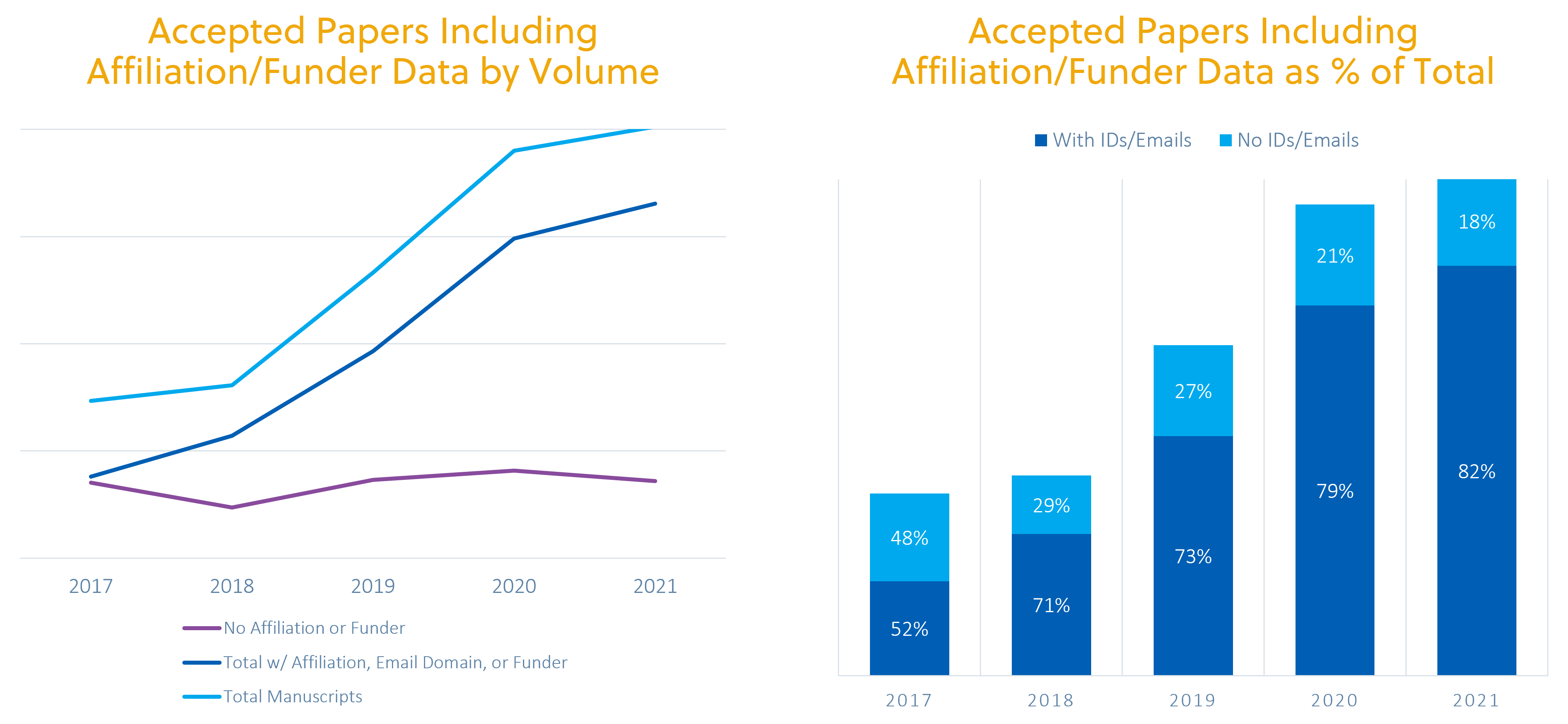
These outcomes are the result of cross-stakeholder investment, primarily publisher-driven, in capturing and curating manuscript metadata. Examples of publisher investments abound, from enterprise data management policies to homegrown processes for auditing, disambiguating and normalizing data to market-driven services that enrich datasets at scale. The data from our RLSC service represents publishers from a broad cross-section of disciplines and capabilities, who benefit from the shared learning on metadata best practices.
All of that said, there is much room for improvement. The information in the charts above is a mix of affiliation IDs, email domains, funder ids, or a combination of these. Unsurprisingly, funder identifiers make up a very small percentage of total IDs. Additionally, far too many matches between a manuscript and an institutional agreement are based on institutional email domains rather than PIDs, and there remain disconnected mechanisms to update author records when affiliations change. Although CCC has developed resolver technology to make up for gaps in metadata during the agreement modeling process (e.g., to distinguish between institutions affiliated with research and those who paid an actual APC), the scale and scope of new mandates as well as new transformative agreements require greater industry attention and collaboration to make OA properly seamless.
CCC is working to improve the use of Persistent Identifiers (PIDs), particularly those with high levels of granularity such as institution PIDs from Ringgold, as they are essential in the successful mapping of co-author affiliations, which are required under mandates such as OSTP’s Nelson Memo. This work would be greatly accelerated by the provision of PIDs in funder, publisher, institution, and submission system metadata for seamless integration into systems that enable managing the flip to Open Access.
To scale any OA business model, the aim should be the ability to construct truly sustainable deals and not sink time and money into laborious agreement modeling and analysis based on unreliable data. Consistent, complete, and correct metadata—with PIDs enabling connections—must be a strategic priority for any publisher embarking on the journey to full and immediate OA.
To learn how CCC can help support your data quality initiatives and agreement modeling processes as you transition your business, please connect with us, and read more about our data-driven modeling solution OA Agreement Intelligence here.
